Conventional K8s cluster management requires available capacity - scheduling unnecessary Pods on excess nodes - for unexpected spikes. This results in significant cost in idle resources, just in case.
Kompass Headroom reduction harnesses HiberScale technology, eliminating the need for excess nodes or Pods, while preserving your SLA.
HiberScale provisions and manages nodes that are prewarmed with downloaded Docker images and prestarted OS. HiberScale puts those nodes into AWS hibernation, ready to be resumed instantaneously.
In case of a spike, HiberScale can resume these nodes to full operational capacity significantly faster than native Kubernetes autoscalers. Scheduled Pods can serve requests within a matter of seconds, enabling applications to run 5 times sooner than standard.
This combination of very quick application boot time together with HiberScale fast scaling saves cost:
Eliminates the initial overprovisioning of nodes and Pods.
During a spike, reduces the need to launch more nodes as the current ones have more headroom.
The following video shows how Headroom reduction reduces the need for an overallocated node buffer:
Limitations
Headroom reduction can be activated only on Deployment-type workloads.
The magic behind the scenes
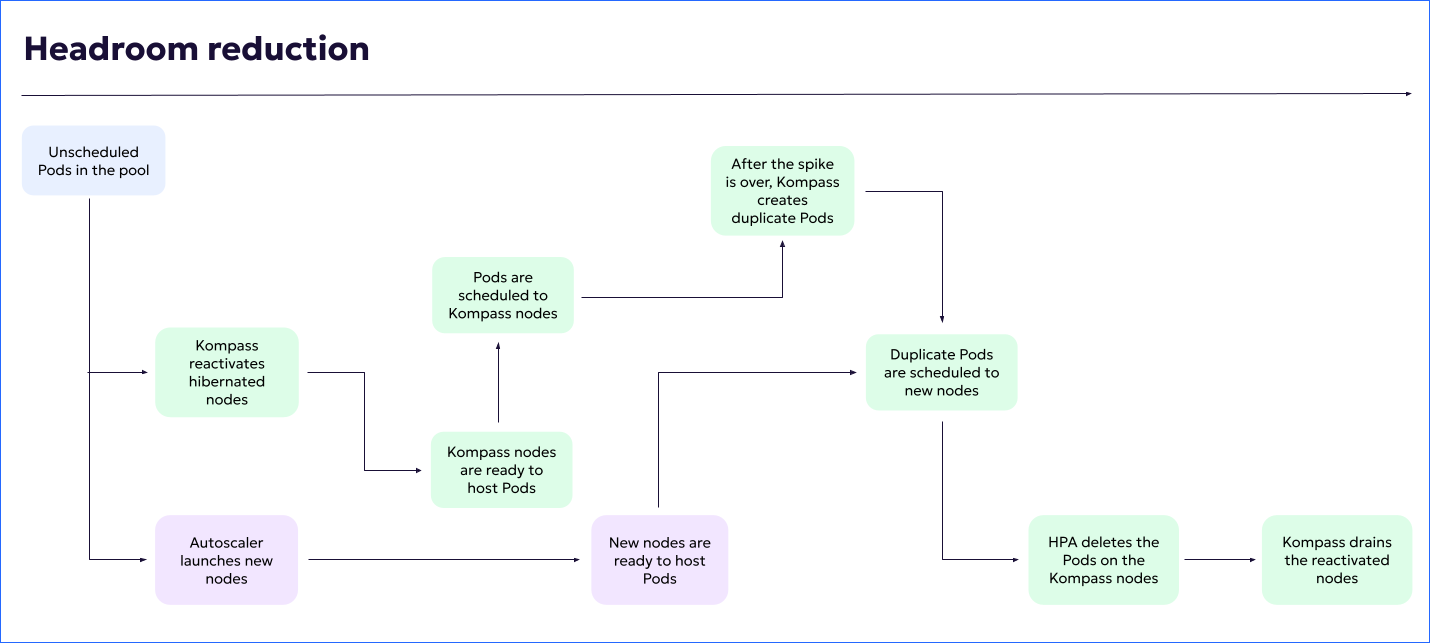
When you activate Headroom reduction on a workload, the following automatic steps ensure protection:
Hibernated nodes begin warming up. Kompass listens to the unscheduled Pods pool.
When Kompass determines that there are unscheduled Pods in the pool, Kompass deploys pre-baked, hibernated nodes to respond to spikes.
At the same time, the autoscaler launches new nodes.
When the Kompass nodes are ready to host Pods, the unscheduled Pods are scheduled to the Kompass nodes.
5 minutes after being reactivated, Kompass hibernated nodes are cordoned.
After the spike is over, Kompass nodes are gradually drained, until all Pods are hosted by autoscaler nodes.
To ensure smooth draining, the number of Pods may exceed the number that were running before the spike.
When Kompass nodes are empty (no more Pods being hosted), the nodes are terminated.
The following diagram illustrates the process: