Many AWS users avoid Spot Instances due to the risks of interruption—Pod eviction, delayed rescheduling, and potential downtime. The result: overreliance on expensive On-Demand nodes.
Kompass Spot Management mitigates these risks using HiberScale technology. Hibernated, prewarmed nodes are ready to resume immediately if a Spot instance is interrupted, allowing evicted Pods to restart well before the instance is terminated.
Kompass also classifies which workloads are suitable for Spot, based on the application configuration and reduced start time. This way, you can safely migrate suitable workloads away from On-Demand without compromising performance.
This combination of rapid resume time and proactive workload protection makes Spot safer:
Protects workloads from Spot interruption without impacting SLA.
Identifies and safely migrates eligible workloads to Spot—reducing dependency on costly On-Demand instances.
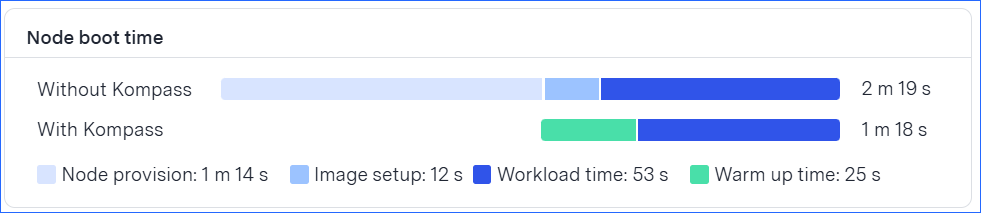
The following figure shows an example of how Kompass launches a hibernated node much faster than the current boot time:
As recommended by Kubernetes and by AWS best practices, you should configure a Pod Disruption Budget (PDB) to limit the number of Pods that can become simultaneously unavailable. A PDB helps ensure that a minimum number of Pods remain available even during the 2 minute notification time of a Spot interruption.
With HiberScale technology, Kompass provisions new nodes in less than 2 minutes.
Pods kept available by the PDB can then be quickly rescheduled to the Kompass nodes before termination.
During large-scale Spot interruptions, the combination of PDB enforcement and rapid node provisioning ensures there is no application downtime.
For this reason, Spot management can be activated only on workloads that have a PDB configured.
If you attempt to activate Spot management for a workload without a PDB, Kompass displays code that you can use to configure it for that workload.
Alternatively, you can use this generic code. Change the environment variables as needed:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: "{{ .Values.deployment.name }}-pdb"
spec:
maxUnavailable: 20%
selector:
matchLabels:
service: "{{ .Values.deployment.name }}"For more information, see this Kubernetes documentation: Specifying a Disruption Budget for your Application.
Prerequisites
PDB is configured for the workload.
Limitations
Spot management can be activated only on Deployment-type workloads, running on clusters where Karpenter is running.
The magic behind the scenes
When you activate Spot management on a workload, the following automatic steps ensure protection:
Kompass ensures that the workload and Karpenter configurations enable using Spot nodes, modifying configurations if necessary.
Hibernated nodes start warming up.
For more information about hibernated nodes, see HiberScale technology.Interruption protection begins immediately for all Pods from protected workloads hosted on Spot instance nodes.
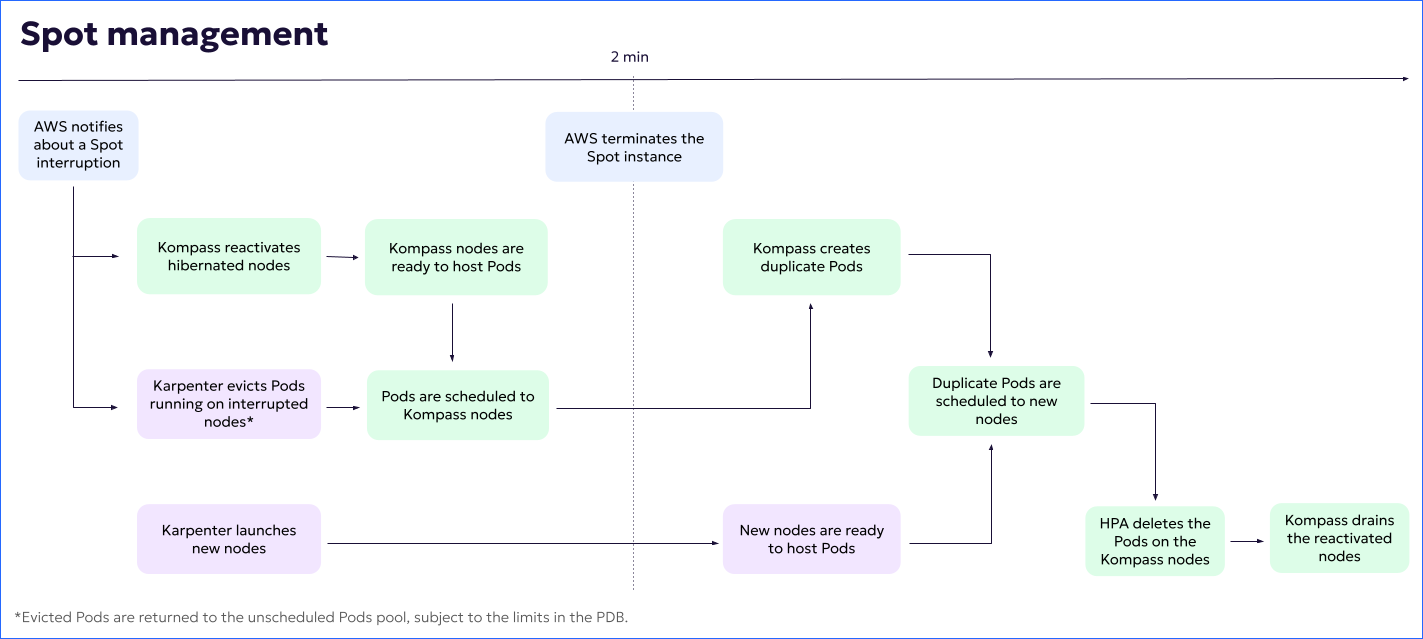
When AWS notifies about a Spot interruption, Kompass reactivates pre-baked hibernated nodes to replace the interrupted nodes.
At the same time, Karpenter evicts the Pods running on the current nodes and launches new nodes.
(Pods are evicted according to the limits in the PDB.)
When the Kompass nodes are ready to host Pods, Pods are scheduled to those nodes.
5 minutes after being reactivated, Kompass hibernated nodes are cordoned.
Kompass nodes are gradually drained, until all Pods are hosted by autoscaler nodes.
To ensure smooth draining, the number of Pods may exceed the number that were running before the interruption.
When Kompass nodes are empty (no more Pods being hosted), the nodes are terminated.
The following diagram illustrates the process: