When you activate Headroom reduction on a workload, the following automatic steps ensure protection:
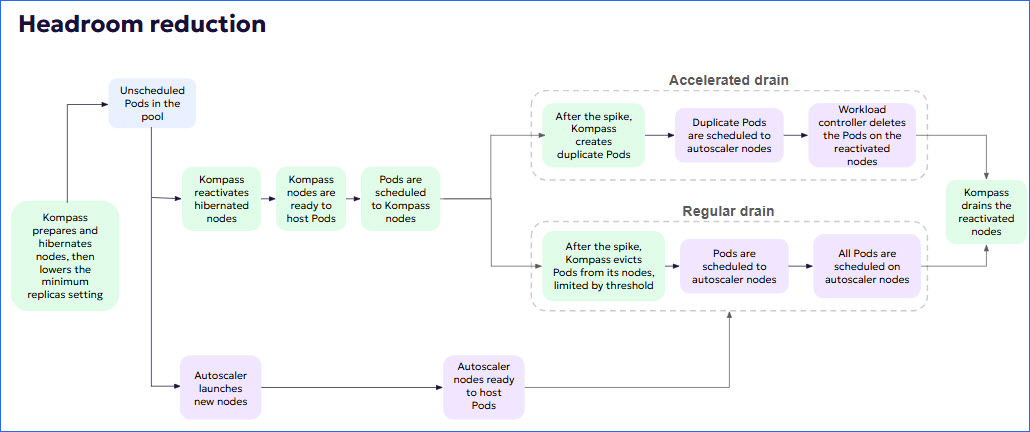
Kompass prepares and then hibernates nodes.
When those nodes are ready, Kompass reduces the minimum replicas setting according to the selected optimization strategy. This process takes about an hour.
Kompass listens to the unscheduled Pods pool.
When Kompass determines that there are unscheduled Pods in the pool, Kompass deploys pre-baked, hibernated nodes to respond to spikes.
At the same time, the autoscaler launches new nodes.
When the Kompass nodes are ready to host Pods, the unscheduled Pods are scheduled to the Kompass nodes.
5* minutes after being reactivated, Kompass hibernated nodes are cordoned.
After the spike is over, Kompass nodes are gradually drained, until all Pods are hosted by autoscaler nodes.
Node draining is defined by the user-defined draining mechanism, described in Node draining mechanisms.
The Kompass nodes are terminated when they are no longer hosting Pods, or 60* minutes after being cordoned, whichever is first.
* You can configure the time period in the QubexConfig CR. For more information, see Apply and manage Headroom reduction with CRD.
Node draining mechanisms
You can choose from these node draining mechanisms:
Accelerated (default): The Pods running on Kompass nodes are duplicated and the duplicates are scheduled on autoscaler nodes. A Kompass Pod is evicted only when its duplicate is running on an autoscaler node.
The number of Pods in the system may exceed the number that were running before the spike.
Regular: The Pods running on Kompass nodes are scheduled on autoscaler nodes. Kompass Pods are evicted, limited to a user-defined threshold. When an evicted Pod begins to run on an autoscaler node, another Kompass Pod is evicted.
There are never more unscheduled Pods than the threshold allows.
The regular mechanism may be more suitable for the following use cases:
Use case | Description |
|---|---|
Workloads with stateful or sticky characteristics | Workloads rely on local state, affinity, or session stickiness and should not have Pods rapidly replaced. |
Workloads registered to ELB / API gateway | Pods require time for graceful deregistration and connection draining; accelerated draining may cause traffic drops or 5xx spikes. |
Workloads with long-lived or sticky connections | Streaming, WebSockets, or gRPC sessions cannot be quickly migrated; gradual eviction prevents disruption. |
Workloads using PreStop hooks or slow shutdown logic | Regular draining respects PreStop hooks and avoids prematurely deleting pods that need extra shutdown time. |
The following diagram illustrates the process:
See also: